Mixing Manual Human Effort with the Power of Machine Learning
I really enjoy watching David Brooks and Mark Shields engage in a civil discussion of the week's news on the Friday broadcast of the PBS News Hour. While I don't always agree with David Brooks' politics, I do think he presents some very rational and pressing arguments in his work (his recent column on weed aside).
In today's New York Times, Brooks critiques our heightened love of machines and the use of automation to replace human dependent tasks like driving cars or picking stocks. Brooks makes the point that even in this age of rapidly expanding technology, there are certain human activities that machines just can't replicate. Brooks is certainly right on some fronts. But maybe the question isn't a dichotomous one -- machine vs. human? Perhaps, as I've seen in my own recent work with a team of computer science colleagues, it's about using machines to enhance human efforts. Relying on techniques from the world of artificial intelligence (e.g., automated machine learning, semi-supervised learning, etc.) can not only make human efforts more efficient but also exponentially increase the amount of data that we as communication researchers are able to process.
In one piece of our current project, my colleagues and I compare the accuracy of traditional manual content analysis coding with automated coding that uses a basic Naive Bayes classifier. Specifically, we're looking at traditional and new media coverage of the same-sex marriage debate in Maryland between 2011-2012. What we've found is that with a little supervision, our automated coding efforts can achieve levels of accuracy greater than 90% suggesting that it may make sense to apply these principles from natural language processing to make sense of even larger bodies of "old media" data.
We've also amassed a dataset of over 9 million tweets to look at new media content. Yet again we've paired manual coding efforts that capture relevancy and sentiment with automated techniques. We applied a Bayes classifier yet again to look at the relevancy of tweets downloaded during 2011-2012 and used support vector machines (SVM) to assess sentiment. The end result -- a much larger set of coded tweets and accurate results (> 90%) when we look at both relevance and sentiment.
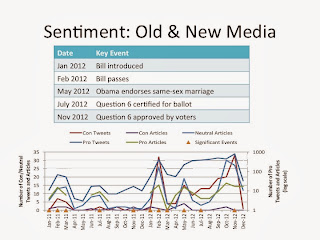 In my opinion, the beauty of this project is the balance between human and machine activity. As a scholar of public opinion research and the marriage equality issue in particular, I bring my domain-specific knowledge to the project, applying public opinion theory and traditional content analysis techniques to the coding of the old and new media data. My computer science colleagues bring their knowledge of machine learning, their desire for high-performing algorithms, and their programming skills to the table. What has resulted is a significant interdisciplinary undertaking that pairs traditional mass communication research approaches with the power of computational social science.
We're now moving beyond the text to analyze the social network driving the Maryland-focused same-sex marriage conversation on Twitter between 2011-2012. And truth be told, none of this would have been possible if we hadn't started out with the idea of connecting man and machine. So perhaps, Mr. David Brooks, it's not about humans vs. machines but how can humans and machines work together to solve common, important problems.
In my opinion, the beauty of this project is the balance between human and machine activity. As a scholar of public opinion research and the marriage equality issue in particular, I bring my domain-specific knowledge to the project, applying public opinion theory and traditional content analysis techniques to the coding of the old and new media data. My computer science colleagues bring their knowledge of machine learning, their desire for high-performing algorithms, and their programming skills to the table. What has resulted is a significant interdisciplinary undertaking that pairs traditional mass communication research approaches with the power of computational social science.
We're now moving beyond the text to analyze the social network driving the Maryland-focused same-sex marriage conversation on Twitter between 2011-2012. And truth be told, none of this would have been possible if we hadn't started out with the idea of connecting man and machine. So perhaps, Mr. David Brooks, it's not about humans vs. machines but how can humans and machines work together to solve common, important problems.




Comments
Post a Comment